【机器学习入门与实践】合集入门必看系列,含数据挖掘项目实战
时间:2025-07-27 15:02:31
该合集涵盖了机器学习的基础知识和实用案例。入门教程介绍了逻辑回归、朴素贝叶斯等多种算法,并通过鸢尾花和企鹅的数据集演示了分类预测的实现方法。实战部分则包括工业蒸汽量预测的情境,涉及到数据预处理、模型训练及验证等环节,同时还有一个二手车价格交易预测项目,帮助读者提升实际操作能力。

【机器学习入门与实践】合集入门必看系列,含数据挖掘项目实战
1. 【机器学习入门与实践】合集入门必看系列
A.机器学习系列入门系列[一]:基于鸢尾花的逻辑回归分类预测:
逻辑回归虽然名称里有“回归”一词,但它本质上是一种分类算法,适用于多种场景。尽管近年来,深度学习成为主流,但在许多领域,传统的逻辑回归仍然表现出色,依旧不可或缺。
A.机器学习算法入门系列(二): 基于鸢尾花数据集的素贝叶斯分类预测
朴素贝叶斯算法(Naive Bayes, NB)是应用最为广泛的分类算法之一。它是基于贝叶斯定义和特征条件独立假设的分类器方法。由于朴素贝叶斯法基于贝叶斯公式计算得到,有着坚实的数学基础,以及稳定的分类效率。NB模型所需估计的参数很少,对缺失数据不太敏感,算法也比较简单。当年的垃圾邮件识别都是基于朴素贝叶斯分类器实现的。如今,随着技术的进步和大数据的应用,朴素贝叶斯已经从一个简单的工具演变成了强大的分析工具。它在文本挖掘、情感分析等领域有着广泛的应用前景。朴素贝叶斯算法不仅具有高度的准确性和稳定性,而且对于大规模数据集也非常友好,因此在实际应用中得到了广泛应用。
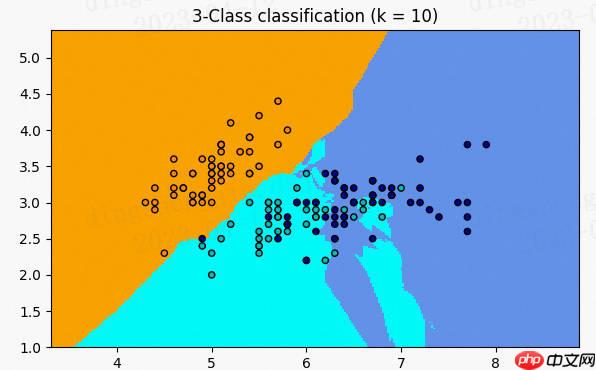
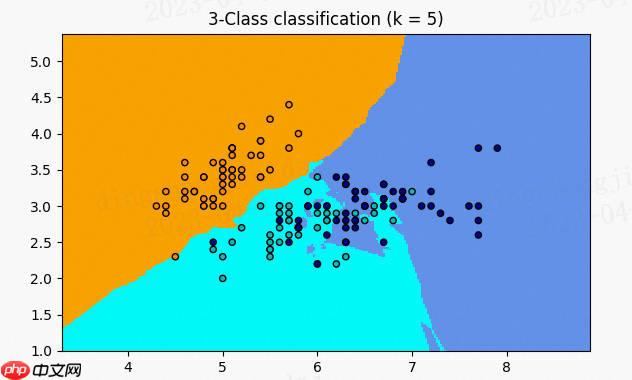
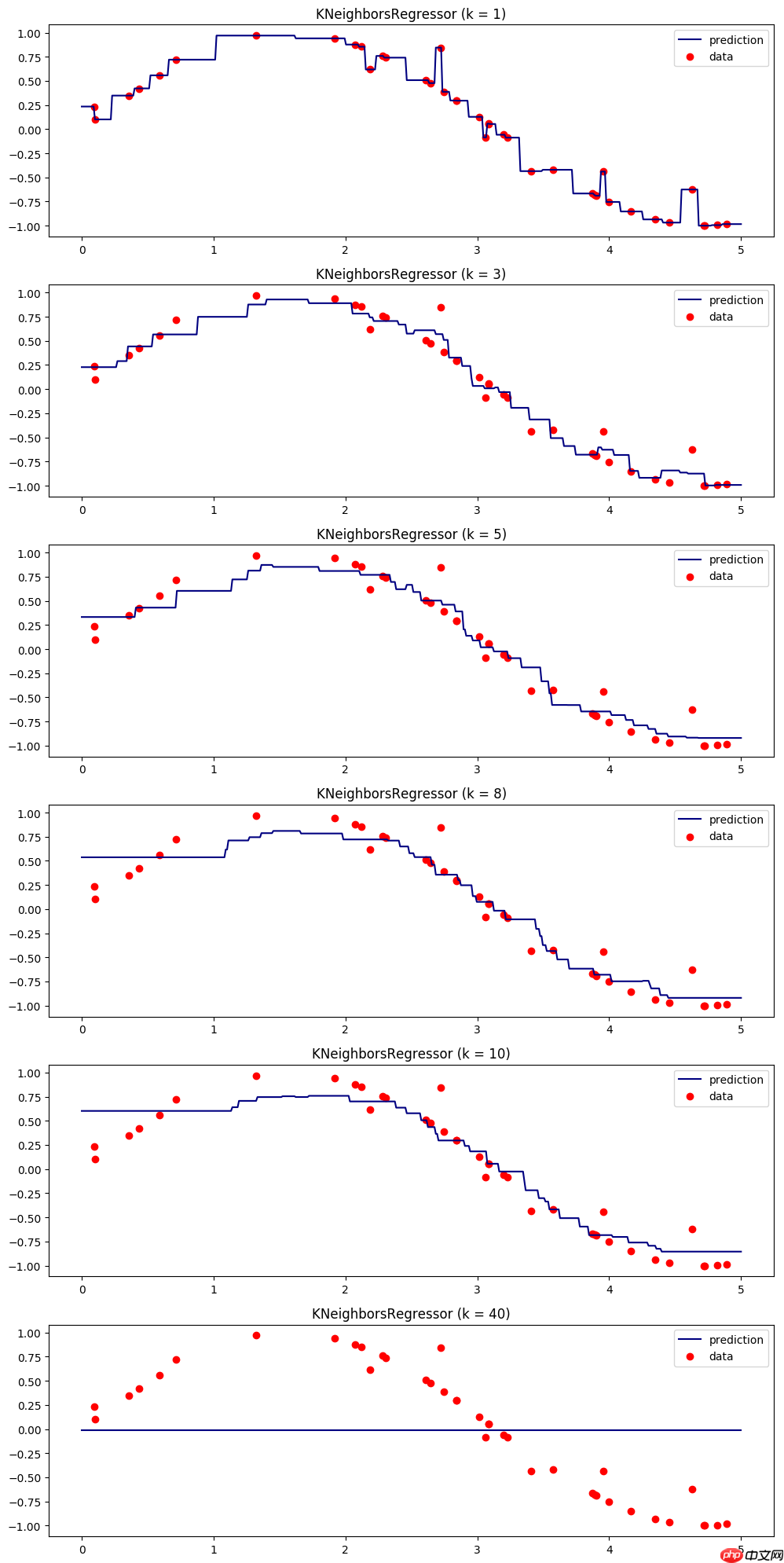
A.机器学习系列入门系列[三]:基于horse-colic的KNN近邻分类预测:
如果你想知道一个人的经济状况,只需考虑他们最好的五个朋友的经济实力,然后取这些朋友的平均值。这是基于K近邻(k-Nearest Neighbors, kNN)算法的思想。
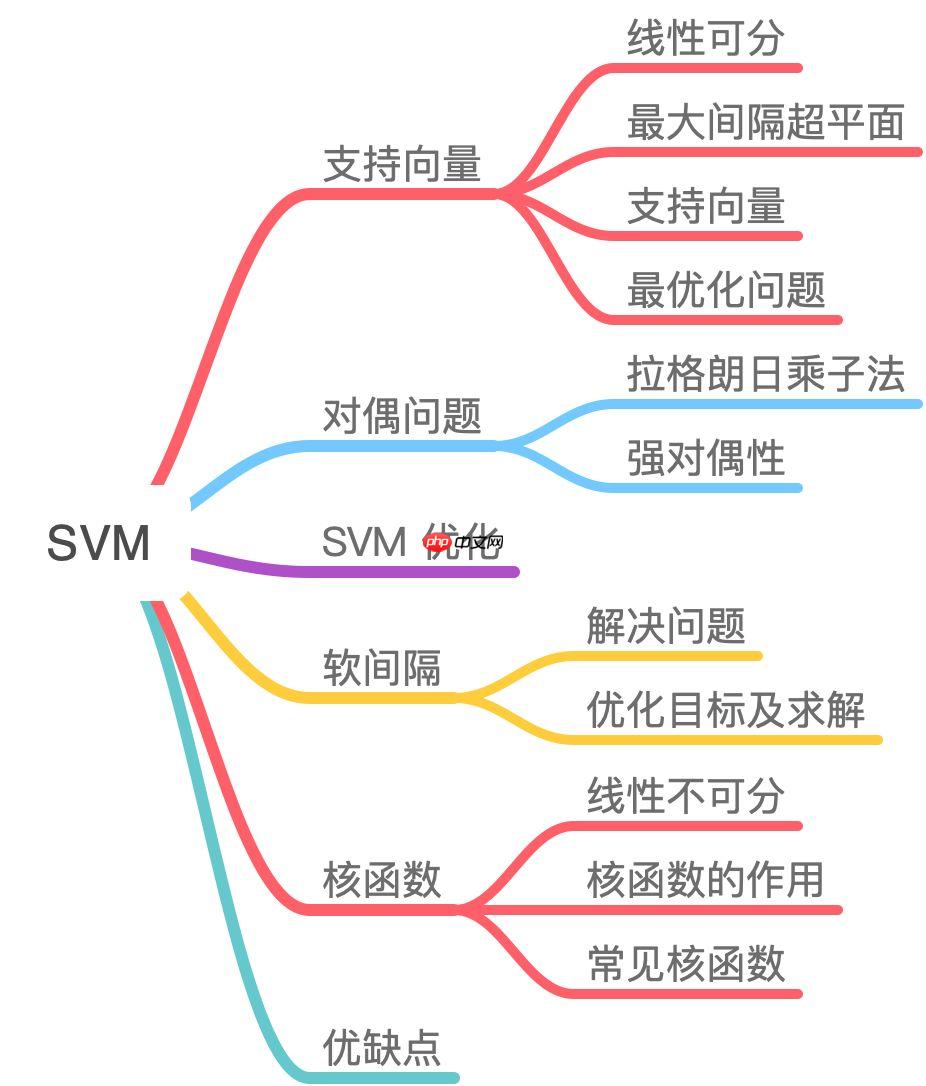
A.机器学习系列入门系列[四]:基于支持向量机的分类预测
支持向量机(SVM)是一种强大的机器学习技术,以其优秀的数学理论著称。它主要用于数据分类和回归预测,特别适用于那些线性不可分的问题。该算法基于优化原理,提供了高度有效的解决方案。此外,SVM还通过核函数技术处理非线性问题,使得其应用范围广泛而强大。
A.机器学习系列入门系列[五]:基于企鹅数据集的决策树分类预测
决策树:分类模型的基石决策树是一种常见的分类模型,在金融风控、医疗辅助诊断等众多行业有着广泛的应用前景。其核心思想在于构建一个由多个分支组成的树状结构来对数据进行划分,这种基于树形结构处理问题的方法是人类处理问题时的一种本能思维模式。与传统方法相比,决策树模型在自变量与因变量之间的非线性关系以及简单的计算方法上具有显著优势。由于其简单且高效的特性,在集成学习中成为最为广泛采用的基模型之一。梯度提升树(GBDT)、XGBoost以及LightGBM等先进集成模型均采用了决策树作为基础模型,这些模型在广告计算、CTR预估、金融风控等多个领域取得了巨大成功,并被广泛应用于数据挖掘竞赛中。 研究新成果:多粒度级联森林近期,南京大学周志华教授提出了一种创新性的方法多粒度级联森林(Multi-granularity Cascade Forest)。这种模型采用了决策树作为基模型,但其核心在于将传统的单一决策树升级为具有多个层次和不同颗粒度的多粒度级联结构。通过这种方式,它能够有效地捕捉数据中的复杂特征,并进一步提升分类性能。在新的研究中,周教授团队展示了如何利用这一方法来解决传统决策树无法有效处理的大规模问题。具体来说,他们提出了一种新颖的数据分层策略和优化算法,使得多粒度级联森林能够在保持高效率的同时显著提高模型的分类准确率。这种创新性的设计为未来数据挖掘领域提供了新的研究方向。 结语通过这一研究成果,决策树不再仅仅是简单的问题解决工具,而是成为复杂数据处理的新典范。周教授的研究进一步证实了传统算法在面对大规模和复杂问题时依然具有强大的适应性和优化潜力。在未来的数据挖掘竞赛和实际应用中,多粒度级联森林有望发挥出更大的作用,并引领整个领域向着更加高效和精准的方向发展。
A.机器学习系列入门系列[六]:基于天气数据集的XGBoost分类预测:
XGBoost,由陈天奇老师领导开发的可扩展机器学习系统。严格意义上讲,它并非单一的模型,而是一个让用户能便捷地解决分类、回归或排序问题的软件库。其内部采用了梯度提升树(GBDT)技术,并在算法上进行了多项优化。凭借其出色的精度与高效的处理速度,在短时间内成为国内外数据挖掘和机器学习领域中的“超大规模武器”。
此外,XGBoost不仅在系统优化和机器学习原理方面进行了深入的考量,还提供了出色的可扩展性、移植性和准确性。与当前流行的解决方案相比,它能在单台机器上实现更快的运行速度,甚至在分布式系统中也能处理数十亿级别的数据。这些特性显著推动了机器学习计算限制的上限。
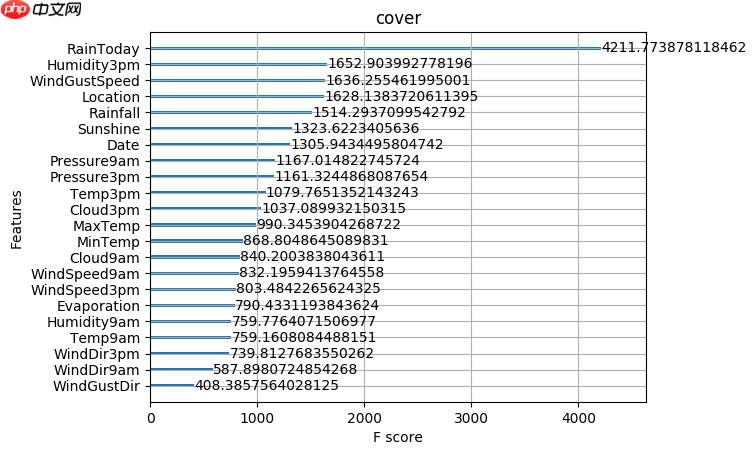
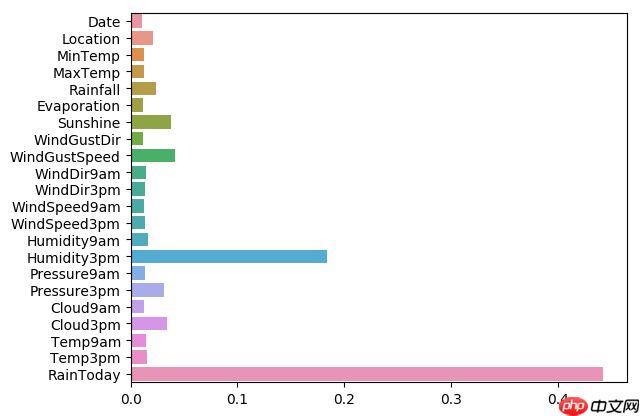
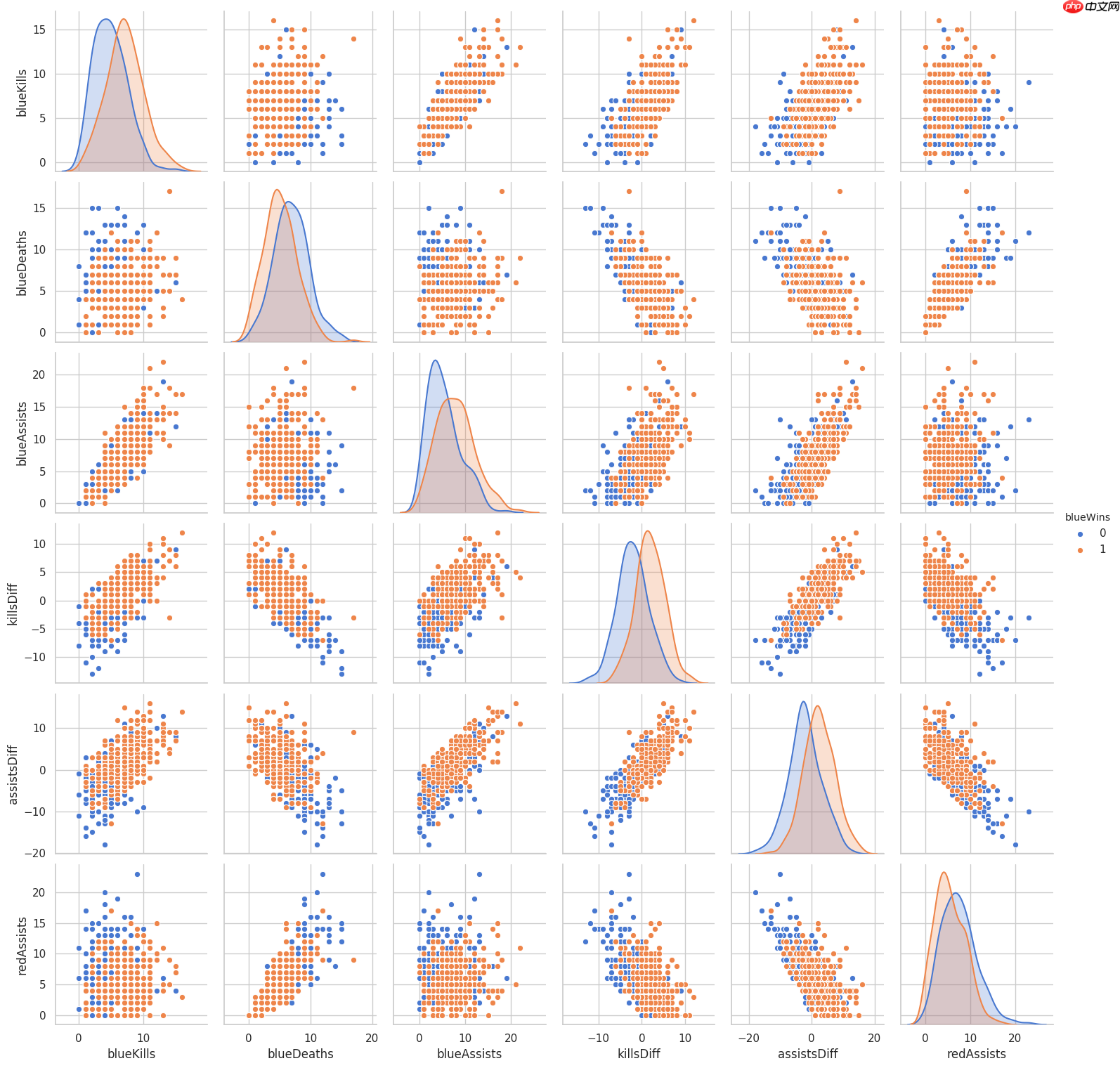
A.机器学习系列入门系列[七]:基于英雄联盟数据的LightGBM分类预测:
LightGBM是由微软推出的一款可扩展机器学习系统,是其旗下DMKT的一个开源项目。它基于GBDT算法开发,设计旨在加速模型计算效率。通过优化数据处理和并行通信策略,LightGBM显著减少了内存占用与运算时间,尤其在多机并行场景下提供了更高的性能提升。
在构建决策树模型时,LightGBM采用了先进的直方图算法进行优化处理,极大地提升了数据存储与运算效率,并确保了模型的稳定性和鲁棒性。一种名为“Leaf-wise”的新的叶节点生长策略被引入到LightGBM中。这种策略抛弃了传统的按层生长(level-wise)的树形结构决策树,转而采用了一种限制深度的按叶子增长(leaf-wise)方法。这不仅提高了模型的整体精度,还减少了计算时间。此外,LightGBM还提出了“单边梯度采样算法”来处理数据中的小样本特征。这种算法通过排除大部分的小梯度样本,只用剩余的样本来计算信息增益,从而在保持精确度的同时显著降低了数据量。更重要的是,LightGBM采用了“互斥特征捆绑(Intersecting Feature Bundling)”的方法来处理高维度稀疏数据。这种方法通过对特征进行无损的捆绑,有效地减少了特征的数量而不牺牲任何信息内容。通常情况下,捆绑在一起的特征都是互斥的,因此不会丢失重要的信息。通过这些独特的优化策略,LightGBM在提升模型效率和精度方面展现出了强大的优势,并成功地在多个基准测试中取得了优异的成绩。
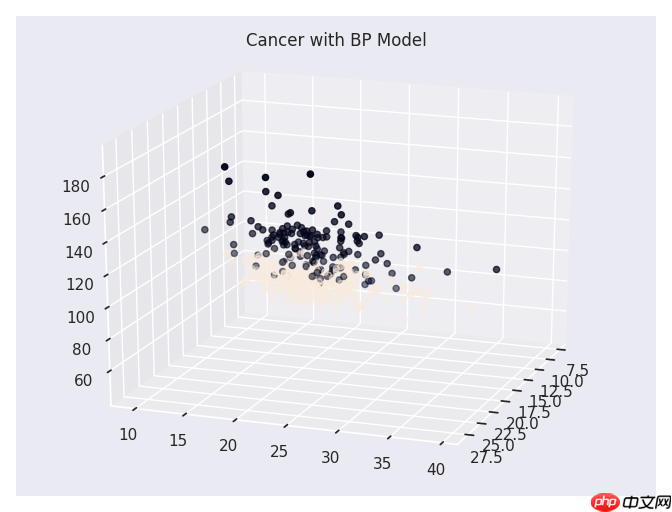
A.机器学习系列入门系列[八]:基于BP神经网络的乳腺ai分类预测
BP(Back Propagation)网络是由Rumelhart和McClelland领导的科学家小组提出的一种多层前馈神经网络,目前在广泛应用于各种领域。BP网络能够学习并存储大量的输入-输出模式映射关系,并且无需事先揭示描述这种映射关系的数学方程。其学习规则采用最速下降法,通过反向传播不断调整网络的权值和阈值,使误差平方和最小化。BP神经网络由输入层、隐层(隐藏层)和输出层组成。在训练过程中收集系统的误差信息,通过误差逆向传播进行调整,最终实现模型整体最优化的目标。这是一个循环的过程,在每次训练神经网络时都要重复这个过程。
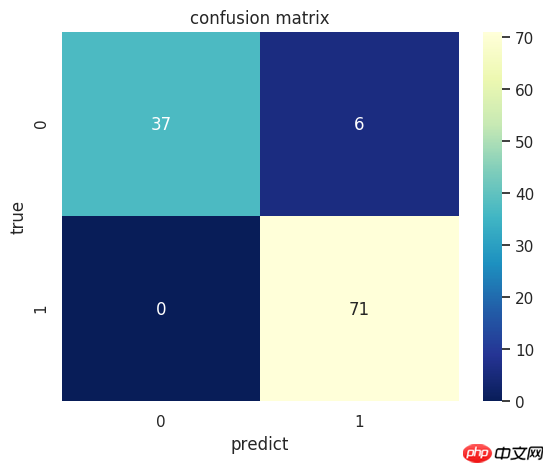
A.机器学习系列入门系列[九]:基于线性判别模型的LDA手写数字分类识别:
线性判别模型(LDA)在模式识别领域如人脸识别等图形图像识别领域有着广泛的应用。LDA是一种监督学习的降维技术,这意味着它的数据集中的每个样本都有类别输出信息。这一特性与无监督降维技术PCA(主成分分析)不同,后者不考虑样本类别。LDA的核心思想可以概括为“投影后类内方差最小,类间方差最大”。我们希望将数据在较低维度上进行投影,使得每一种类别的数据点尽可能靠近其自己的“群体”,而不同类别的数据间的距离尽可能拉大。具体来说,我们将数据投影到更低的维度空间中,这样能使得投影后的点形成一类群一簇的情况,即相同类别的点会聚在一起,而在降维后的空间中他们与不同类别点的距离将变得较大。这种模型有助于识别和分类各种图像模式,并且在提高算法性能的同时也能减少所需的计算资源。通过LDA,我们可以更有效地利用数据信息并更好地理解其结构。
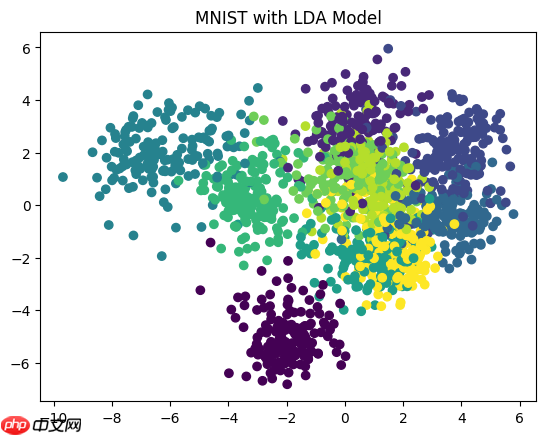
2. 数据挖掘项目实战
B.机器学习实战系列[一]:工业蒸汽量预测(最新版本上篇)含数据探索特征工程等:
B.机器学习实战系列[一]:工业蒸汽量预测(最新版本下篇)含特征优化模型融合等:
在火力发电过程中,燃料首先在锅炉中通过燃烧产生高温高压蒸汽,进而驱动汽轮机进行能量转换,最终生成电能。这一过程中的关键效率提升在于优化锅炉燃烧性能与控制参数。锅炉燃烧效率直接影响发电效率,其影响因素包含多种可调参数和工况条件,如燃烧量、一次风及二次风的比例、引风和返料风的配置、给水量等,以及炉膛温度、压力、过热器温度等因素。锅炉燃烧效率的提升需要精准控制与优化,通过调整这些关键参数来实现。例如,改善燃料与空气的比例关系可以提高燃烧效率;合理调控燃烧量有助于减少有害气体排放并节省能源。此外,精确控制炉膛温度和压力也是保证锅炉稳定运行的关键因素之一。通过不断探索和优化燃烧方式,火力发电厂能够在保持安全与经济性的前提下实现更高的能源转化率。
经过去敏感化处理的锅炉传感器数据(按分钟间隔收集)用于预测产生蒸汽的数量,适应不同的运行条件。
数据分为训练集(train.txt)和测试集(test.txt),包含特征字段“VV,用于构建模型预测目标变量“target”。参赛者使用训练数据训练模型后,对测试数据进行预测并计算预测误差,最终排名依据MSE(均方误差)得分。
结果评估 预测结果以mean square error作为评判标准。
在工业蒸汽量预测上篇中,主要讲解了数据探索性分析:查看变量间相关性以及找出关键变量;数据特征工程对数据精进:异常值处理、归一化处理以及特征降维;在进行归回模型训练涉及主流ML模型:决策树、随机森林,lightgbm等。下一篇中将着重讲解模型验证、特征优化、模型融合等。
【机器学习入门与实践】数据挖掘-二手车价格交易预测:
来自Ebay和Kleinanzeigen的二手车库存数据总量超过,其中包含变量信息,旨在确保比赛的公平性。为此,将从中随机抽取条作为训练集,条分别作为测试集A和B,进行严格的数据分析与评估。在脱敏处理过程中,我们将对车辆名称、类型、变速箱、型号、燃油类型、品牌、公里数以及价格等敏感信息进行全面屏蔽,以保证数据的安全性和隐私性。
以上就是【机器学习入门与实践】合集入门必看系列,含数据挖掘项目实战的详细内容,更多请关注其它相关文章!
相关下载
相关资讯
猜你喜欢
最新资讯
-

试玩开启!《宝可梦传说Z-A》将参加科隆游戏展
2025-07-27
近日,宝可梦官方宣布宝可梦传说Z-A将在年内参加科隆游戏展,于至期间在德国科隆举办。玩家可以提前体验这款游戏
-

专业绘画软件有哪些 好用的绘画软件排行榜
2025-07-27
在绘画的世界里,每个人都有各自的梦想。有人因为学业的需要而必须掌握绘画技巧;也有人是纯粹地喜爱,长期投身于这个艺术领域
-

《头号追击》正式上线,网易携前拳头团队打造MOBA+射击+吃鸡混合新体验
2025-07-27
近日,网易发行的多人竞技新作Supervive已于成功开启服务器。该游戏由TheorycraftGames工作室研发,凭借其独特的创新理念和顶级开发团队,包括曾参