百度网盘AI大赛水印智能消除赛:第8名方案
时间:2025-08-02 11:22:23
本文探讨水印擦除任务与手写文字擦除的异同点及其处理难点。数据处理方面,涉及生成mask、缩小数据集及随机裁剪的方法。模型训练采用Erasenet进行,并调整损失函数;在B榜中则优化了模型结构以提升性能。最后,提供了一套完整的模型优化和使用说明。

一、赛题解读
1、赛题分析
赛题任务需要对添加了水印的图像,将水印擦除掉,还原原本的图的样子(图1)。
与手写文字擦除任务(图的一个显著区别在于,水印占据较大空间,这使得在处理被擦除区域时需要额外填补填充,这是本项目的重点和挑战所在。
结论:当前仅用单一语义分割方法无法取得理想效果,必须采用包含生成能力的imgmg模型。以下是示例两张对比图像: 图左(带有水印的手写图片),图右(与之对应的原始照片)。 图左(带手写的图片),图右(真实场景照片)。


2、数据处理
数据处理的方式决定了模型的设计,也会对预测的精度产生较大的影响。
为了展示引导模型进行预测,需要结合GT和图片生成掩码(如下图)。参考Erasenet论文中对比结果,带有预测掩码的模型的PSNR普遍高于纯的图像到图像转换。从GoogLeNet也可得到启示,添加预测掩码分支可更有效地实现梯度传递。

经过本次比赛的数据处理,我们发现图像数量庞大,总计本体图片,并且每张图片生成了带水印的版本。最终数据集规模达到了总数据量接近。然而,在模型推理出mask位置时依然存在一定的挑战性,尽管mask本身具有规律性,但生成效果仍需进一步提升。为了解决这个问题,我们决定对原始数据集进行调整,将图像数量从至这样不仅大大降低了数据量(不到),还使得模型训练可以在Aispace上轻松加载和处理,极大地提升了效率。
(3)、参考手写文字擦除,我们同样将图片进行裁剪(随机裁剪至512, 512大小),对密集预测型任务不使用resize。 图3、手写文字擦除baseline,使用了resize导致生成的图像非常的模糊,非常影响psnr)

3、模型训练及预测
A榜采用的是Erasenet技术,其原理与手写文字擦除类似。我们在损失函数方面进行了优化,因为这种直接方式效果显著,能更有效地调整模型训练轨迹,而无需设计过于复杂。以下是模型的结构图:
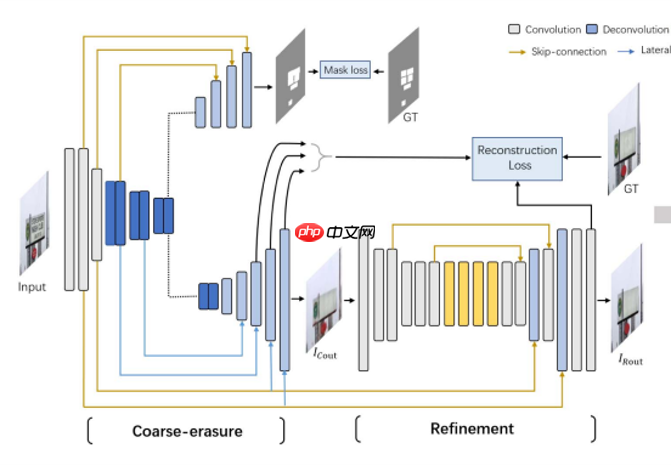
当进行图像预测时,将原始图像重叠分割成小的小块,并对每个小块执行如下操作:对于模型预测为掩码的区域, - 将该区域内预处理后的图片(预处理包括去除噪点)乘以掩码,以保留关键特征。 - 对于非掩码区域,则直接使用原始输入图片。这种方法确保了在没有显著变化的地方保持像素差值接近因为模型输出通常比原图更干净),从而提高了预测的准确性。
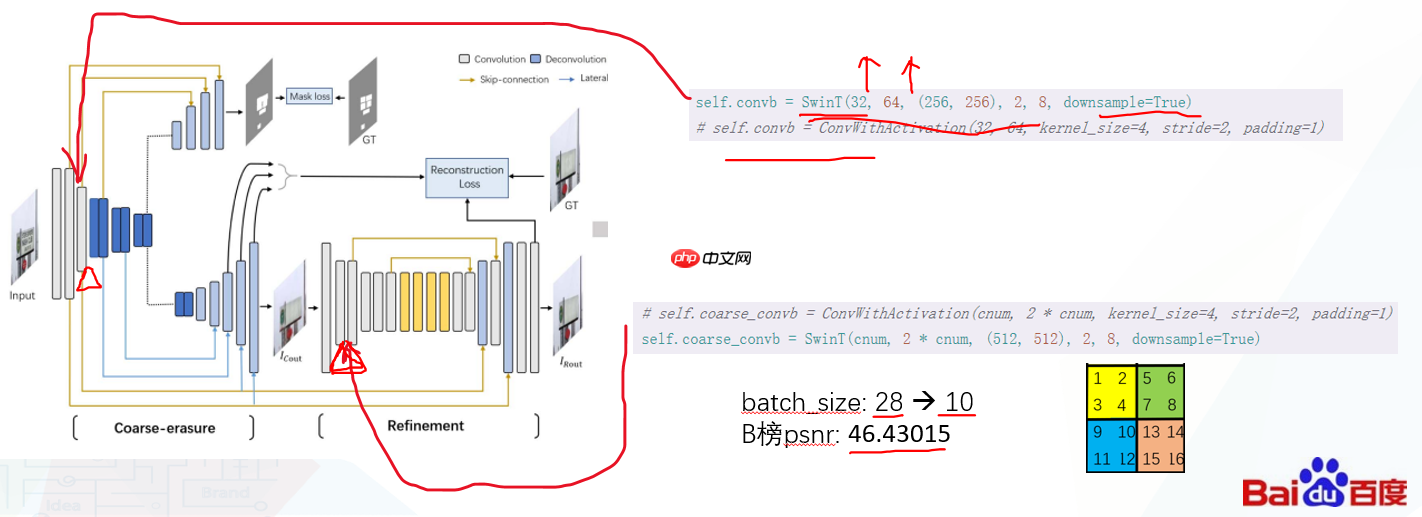
经过B榜对模型进行调优的实验,发现将网络最开始下采样和精修部分下采样的卷积替换为SwinT模块后,显著提升了性能。在验证集上,PSNR值分别达到了相较于原始架构有明显改善。通过这种方式结合了Swin和CNN的优点,实现了模型的加速和高效性。以下是原Erasenet及带swin版本改后的表现对比:图从左到右依次为img, 原始erasenet,erasenet改,gt

4、模型优化
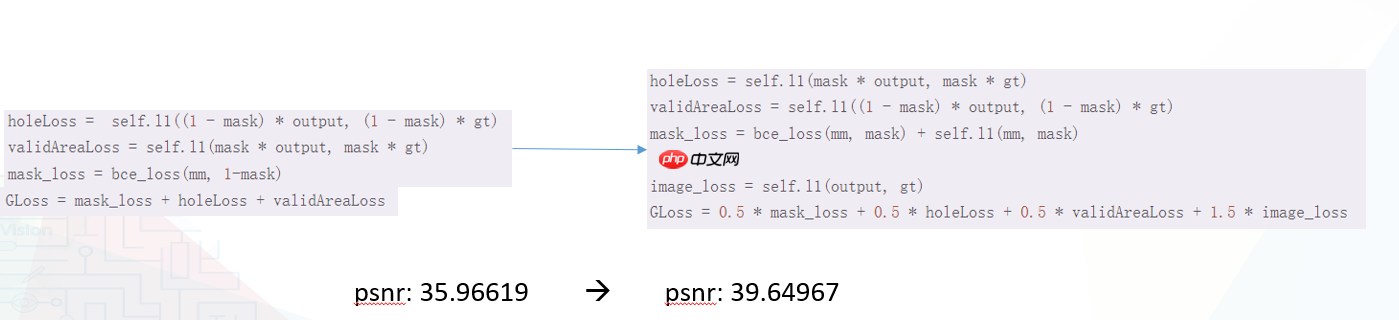
损失函数在所有超参数调整中最重要,因为它直接面对数据集。
优化损失函数策略:我不仅在mask损失上使用了bce,还添加了l为辅助损失。为了提高图像质量并使生成结果更加规整,我们显著提高了image_loss的权重,从原来的加到尽管其他损失项进行了相应调整,但整体效果显著提升了psnr。
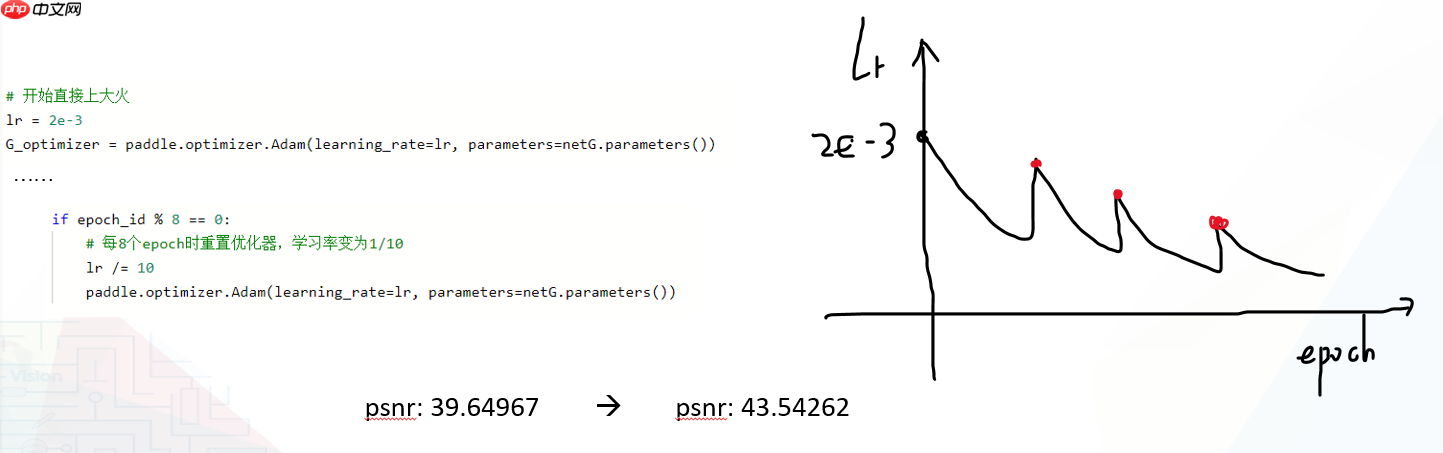
在优化器调整中最优先考虑的是模式选择,因为它直接决定了训练何时能达到最佳状态。
每次重新调用优化器,实际上是对模型加载一个已经预先训练好的基础模型。这有助于确保后续的训练过程更加稳定,并且能够有效避免陷入局部平滑区域,防止过拟合的发生。通过这种方式,模型可以更快地收敛到更好的解状态。
(3)、结构调整: 在所有超参数的调整中,我们把网络结构放在第三位置,因为其难调整,需要训练到平稳才能看出模型的好坏。
因为该任务,生成非常困难,尤其是在彩色水印嵌入在彩色图像中后,尽管能够检测到掩码,但生成的效果并不理想。
二、本项目使用说明
由于本次比赛要求上传模型及其参数文件,不再需要额外生成或展示模型推理过程的相关代码。这使得我们主要关注的是模型的训练方法和优化策略,从而更加专注于提升模型性能和效果。
首先运行下面cell的代码,对数据集进行解压。 In []
# 解压文件!unzip -oq data/data145795/train_dataset.zip -d ./dataset !unzip -oq data/data145795/valid_dataset.zip -d ./dataset登录后复制
1、数据处理
数据处理方式影响模型设计与预测精度在处理手写文字擦除任务时,与传统的水印遮挡任务不同,此项目的一大挑战在于水印占据面积较大。为了解决这一难题,需要对被擦除的区域进行填补。为了展示指导模型准确地预测水印消除后的图像,首先需将原图、真实图片和掩膜(使用自己编写代码生成)结合gt与img差值后形成mask。下图是示例:
尽管本次比赛的数据集规模庞大,包含本体图像以及每张图生成了带水印的新图像,总共达到了约的数据量。然而,在训练过程中,模型虽然能够轻松识别出mask的位置,但由于生成过程中的细节处理不够精细,导致最终效果并不理想。因此,为了提升生成的效果,扩充数据集显得尤为重要。具体而言,应寻找这些本体图像在分布上的规律性,并以此为基础进行数据的补充和优化,以期达到更佳的视觉效果。
虽然机器学习理论告诉我们,增加训练数据量可以提升模型效果并减少过拟合的风险;然而,在现实情况下,我们实际上只能处理一个批次的训练数据,并且这一过程中的梯度影响可能会在后续的小批次中被逐渐抹除。反向传播算法决定了无法实现增量学习,这意味着较大的训练数据集并不一定带来预期的好处。在这种条件下,显存资源有限的情况下,保持训练数据规模在一个合理范围内(如B以内)是至关重要的。这样做不仅加快了模型的加载速度,还能保证预测精度不下降,从而提高整体项目效率。
采用随机裁剪处理图片(尺寸调整为,避免在密集预测任务中应用resize方法。
总结如下:我们在数据处理方面采用了三重策略:将原始数据减少到B,采用掩码指导模型进行训练,并通过随机裁剪调整图像大小至这种方法显著提高了模型性能和资源利用效率。
2、模型搭建
A榜采用了Erasenet架构进行模型开发,代码参考自https://aistudio.baidu.com/aistudio/projectdetail/我们使用了与手写文本擦除相似的方法来调整损失函数,这是因为直接优化面向真实数据的损失函数比设计复杂模型更为有效。我们的目标是通过改变训练过程中的主要评估标准来实现这一点。整体架构如下图所示: 图Erasenet 主体结构
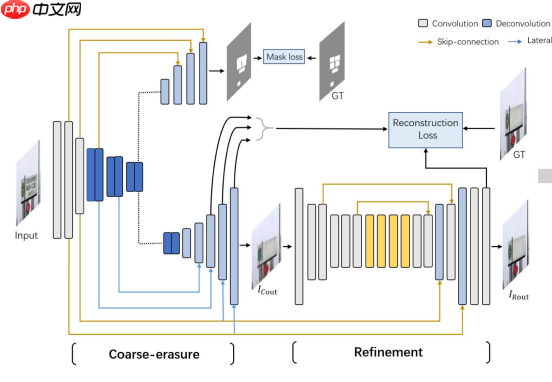
模型数据流向大体如上,loss的地方做了一定的修改。
B榜对模型进行了优化调整,将网络最开始下采样和精修部分替换成了SwinT模块,这一改变不仅提高了模型性能,还显著提升了验证集的PSNR值。具体来看,原始Erasenet和带有SwinT改版的Erasenet在验证集上的表现如下:原始图像(Image);原始Erasenet;带有SwinT改版的Erasenet;GT。图展示了这一调整前后模型的表现对比,其中PSNR值分别为这再次证明了SwinT单个模块的强大性能!

3、训练模型
运行trainstr.ipynb可训练原始erasenet,并包含日志log和最优模型,方便使用visualdl进行可视化。虽然最后可能不用于实际提交,但保留此模型仍具有参考价值,因为其batchsize为因此训练速度更快。
以下是关于`erasenet`改版分两部分训练方法及其使用指南:开始时采用A行模型训练,但其只能运行时。将最好模型加载至V续训练,并运行trainswinv可。log_swin和log_swin_v含了完整的日志记录。我们之所以选择A因为时间紧迫,但这并非必要条件。使用V样能够进行大量训练,且无需额外费用或特殊配置。
import warnings warnings.filterwarnings("ignore")# 进行训练from visualdl import LogWriterimport osimport paddleimport paddle.nn as nnimport paddle.nn.functional as Ffrom paddle.io import DataLoaderfrom dataset.data_loader import TrainDataSet, ValidDataSetfrom loss.Loss import LossWithGAN_STE, LossWithSwinfrom models.swin_gan import STRnet2_changeimport utilsimport randomfrom PIL import Imageimport matplotlib.pyplot as pltimport numpy as npimport math %matplotlib inline log = LogWriter('log_swin_v100')def psnr(img1, img2): mse = np.mean((img1/1.0 - img2/1.0) ** 2 ) if mse < 1.0e-10: return 100 return 10 * math.log10(255.0**2/mse)# 训练配置字典CONFIG = { 'numOfWorkers': 0, 'modelsSavePath': 'train_models_swin_v100', 'batchSize': 10, 'traindataRoot': 'dataset/dataset', 'validdataRoot': 'dataset/valid_dataset', 'pretrained': 'train_models_swin/STE_15_43.2223.pdparams', 'num_epochs': 100, 'net': 'str', 'lr': 1e-4, 'lr_decay_iters': 40000, 'gamma': 0.5, 'seed': 9420}# 设置gpuif paddle.is_compiled_with_cuda(): paddle.set_device('gpu:0')else: paddle.set_device('cpu')# 设置随机种子random.seed(CONFIG['seed']) np.random.seed(CONFIG['seed']) paddle.seed(CONFIG['seed'])# noinspection PyProtectedMemberpaddle.framework.random._manual_program_seed(CONFIG['seed']) batchSize = CONFIG['batchSize']if not os.path.exists(CONFIG['modelsSavePath']): os.makedirs(CONFIG['modelsSavePath']) traindataRoot = CONFIG['traindataRoot'] validdataRoot = CONFIG['validdataRoot'] TrainData = TrainDataSet(training=True, file_path=traindataRoot) TrainDataLoader = DataLoader(TrainData, batch_size=batchSize, shuffle=True, num_workers=CONFIG['numOfWorkers'], drop_last=True) ValidData = ValidDataSet(file_path=validdataRoot) ValidDataLoader = DataLoader(ValidData, batch_size=1, shuffle=True, num_workers=0, drop_last=True) netG = STRnet2_change()if CONFIG['pretrained'] is not None: print('loaded ') weights = paddle.load(CONFIG['pretrained']) netG.load_dict(weights)# 开始直接上大火lr = 2e-3G_optimizer = paddle.optimizer.Adam(learning_rate=lr, parameters=netG.parameters()) loss_function = LossWithGAN_STE()print('OK!') num_epochs = CONFIG['num_epochs'] mse = nn.MSELoss() best_psnr = 0iters = 0for epoch_id in range(1, num_epochs + 1): netG.train() if epoch_id % 8 == 0: # 每8个epoch时重置优化器,学习率变为1/10 lr /= 10 paddle.optimizer.Adam(learning_rate=lr, parameters=netG.parameters()) for k, (imgs, gts, masks) in enumerate(TrainDataLoader): iters += 1 fake_images, mm = netG(imgs) G_loss = loss_function(masks, fake_images, mm, gts) G_loss = G_loss.sum() #后向传播,更新参数的过程 G_loss.backward() # 最小化loss,更新参数 G_optimizer.step() # 清除梯度 G_optimizer.clear_grad() # 打印训练信息 if iters % 100 == 0: print('epoch{}, iters{}, loss:{:.5f}, net:{}, lr:{}'.format( epoch_id, iters, G_loss.item(), CONFIG['net'], G_optimizer.get_lr() )) log.add_scalar(tag="train_loss", step=iters, value=G_loss.item()) # 对模型进行评价并保存 netG.eval() val_psnr = 0 # noinspection PyAssignmentToLoopOrWithParameter for index, (imgs, gt) in enumerate(ValidDataLoader): _, _, h, w = imgs.shape rh, rw = h, w step = 512 pad_h = step - h if h < step else 0 pad_w = step - w if w < step else 0 m = nn.Pad2D((0, pad_w, 0, pad_h)) imgs = m(imgs) _, _, h, w = imgs.shape res = paddle.zeros_like(imgs) mm_out = paddle.zeros_like(imgs) mm_in = paddle.zeros_like(imgs) input_array = [] i_j_list = [] for i in range(0, h, step): for j in range(0, w, step): if h - i < step: i = h - step if w - j < step: j = w - step clip = imgs[:, :, i:i + step, j:j + step] input_array.append(clip[0]) i_j_list.append((i, j)) # 并行处理进行加速 input_array = paddle.to_tensor(input_array) input_array = input_array.cuda() with paddle.no_grad(): g_images, mm = netG(input_array) g_images, mm = g_images.cpu(), mm.cpu() for idx in range(len(i_j_list)): i, j = i_j_list[idx] mm_in[:, :, i:i + step, j:j + step] = mm[idx] g_image_clip_with_mask = imgs[:, :, i:i + step, j:j + step] * (1 - mm[idx]) + g_images[idx] * mm[idx] res[:, :, i:i + step, j:j + step] = g_image_clip_with_mask mm_out[:, :, i:i + step, j:j + step] = mm[idx] # for i in range(0, h, step): # for j in range(0, w, step): # if h - i < step: # i = h - step # if w - j < step: # j = w - step # clip = imgs[:, :, i:i + step, j:j + step] # clip = clip.cuda() # with paddle.no_grad(): # g_images_clip, mm = netG(clip) # g_images_clip = g_images_clip.cpu() # mm = mm.cpu() # clip = clip.cpu() # mm_in[:, :, i:i + step, j:j + step] = mm # # mm = paddle.where(F.sigmoid(mm) > 0.5, paddle.zeros_like(mm), paddle.ones_like(mm)) # # g_image_clip_with_mask = clip * mm + g_images_clip * (1 - mm) # g_image_clip_with_mask = clip * (1 - mm) + g_images_clip * mm # res[:, :, i:i + step, j:j + step] = g_image_clip_with_mask # mm_out[:, :, i:i + step, j:j + step] = mm res = res[:, :, :rh, :rw] mm_out = mm_out[:, :, :rh, :rw] # 改变通道 output = utils.pd_tensor2img(res) target = utils.pd_tensor2img(gt) mm_out = utils.pd_tensor2img(mm_out) mm_in = utils.pd_tensor2img(mm_in) psnr_value = psnr(output, target) print('psnr: ', psnr_value) if index in [2, 3, 5, 7, 11]: fig = plt.figure(figsize=(20, 10),dpi=100) # 图一 ax1 = fig.add_subplot(2, 2, 1) # 1行 2列 索引为1 ax1.imshow(output) # 图二 ax2 = fig.add_subplot(2, 2, 2) ax2.imshow(mm_in) # 图三 ax3 = fig.add_subplot(2, 2, 3) ax3.imshow(target) # 图四 ax4 = fig.add_subplot(2, 2, 4) ax4.imshow(mm_out) plt.show() del res del gt del target del output val_psnr += psnr_value ave_psnr = val_psnr / (index + 1) print('epoch:{}, psnr:{}'.format(epoch_id, ave_psnr)) log.add_scalar(tag="valid_psnr", step=epoch_id, value=ave_psnr) paddle.save(netG.state_dict(), CONFIG['modelsSavePath'] + '/STE_{}_{:.4f}.pdparams'.format(epoch_id, ave_psnr )) if ave_psnr > best_psnr: best_psnr = ave_psnr paddle.save(netG.state_dict(), CONFIG['modelsSavePath'] + '/STE_best.pdparams')登录后复制
4、模型预测
```python# 保存模型预测部分的代码在predict.py文件中,与训练过程中对模型进行评估的方法一致。 # 预测为mask的部分使用模型输出,预测为非mask的部分则用输入图片的像素值。这样,在非mask区域可以保证像素差接近因为jpg图像本身存在噪声,通常达不到。```
import osimport sysimport globimport jsonimport cv2import paddleimport paddle.nn as nnimport paddle.nn.functional as Ffrom models.sa_gan import STRnet2# 加载STRnet改from models.swin_gan import STRnet2_changeimport utilsfrom paddle.vision.transforms import Compose, ToTensorfrom PIL import Image netG = STRnet2_change() weights = paddle.load('train_models_swin_v100/STE_12_44.8510.pdparams') netG.load_dict(weights) netG.eval()def ImageTransform(): return Compose([ToTensor(), ]) ImgTrans = ImageTransform()def process(src_image_dir, save_dir): image_paths = glob.glob(os.path.join(src_image_dir, "*.jpg")) for image_path in image_paths: # do something img = Image.open(image_path) inputImage = paddle.to_tensor([ImgTrans(img)]) _, _, h, w = inputImage.shape rh, rw = h, w step = 512 pad_h = step - h if h < step else 0 pad_w = step - w if w < step else 0 m = nn.Pad2D((0, pad_w, 0, pad_h)) imgs = m(inputImage) _, _, h, w = imgs.shape res = paddle.zeros_like(imgs) for i in range(0, h, step): for j in range(0, w, step): if h - i < step: i = h - step if w - j < step: j = w - step clip = imgs[:, :, i:i + step, j:j + step] clip = clip.cuda() with paddle.no_grad(): g_images_clip, mm = netG(clip) g_images_clip = g_images_clip.cpu() mm = mm.cpu() clip = clip.cpu() # mm = paddle.where(F.sigmoid(mm) > 0.5, paddle.zeros_like(mm), paddle.ones_like(mm)) # g_image_clip_with_mask = clip * mm + g_images_clip * (1 - mm) g_image_clip_with_mask = g_images_clip * mm + clip * (1 - mm) res[:, :, i:i + step, j:j + step] = g_image_clip_with_mask res = res[:, :, :rh, :rw] output = utils.pd_tensor2img(res) # 保存结果图片 save_path = os.path.join(save_dir, os.path.basename(image_path)) cv2.imwrite(save_path, output) if __name__ == "__main__": assert len(sys.argv) == 3 src_image_dir = sys.argv[1] save_dir = sys.argv[2] if not os.path.exists(save_dir): os.makedirs(save_dir) process(src_image_dir, save_dir)登录后复制
以上就是百度网盘AI大赛水印智能消除赛:第8名方案的详细内容,更多请关注其它相关文章!


