【AI达人训练营第三期】手工搭建Resnet101分类道路情况
时间:2025-08-07 10:07:10
基于ResNet经网络的道路垃圾识别项目本文介绍了一项基于ResNet经网络的智慧环卫道路垃圾识别项目。首先,我们阐述了在智慧环卫领域的背景及项目的重大意义,接下来详细介绍了数据集处理过程,包括解压缩、分离训练集与测试集、预处理以及自定义数据集的建立。然后,深入讲解了如何使用ResNet络搭建模型、优化器、损失函数和训练阶段的过程,以及如何在预测阶段实现准确识别的道路垃圾。最后总结了该项目在减少环卫劳动力方面的重要贡献。

1.前言
1.1.交流
在学习深度学习的过程中,正确的态度和方法至关重要。首先,设定明确的学习目标,并且坚持不懈地努力是取得进步的关键。通过实际项目实践来加深理解,可以更有效地将理论知识应用于解决真实问题中。在这个过程中,可能会遇到各种挑战和错误,但重要的是要勇于承认并从中学习。本文提供了一个深度学习项目的初步想法和思路,希望对正在学习或准备入门的人有所帮助。无论你是否有经验,这段文字都是一个向你展示如何开始的第一步。如果你有任何疑问或需要进一步的信息,请随时留言。
如果有什么看不懂的地方就从官网文档下手!只有官网文档才是最详细的讲解。
模型入门开发
paddle指令详细讲解!
1.2.项目背景
环境卫生代表了一个城市的形象,智慧环卫则是提升城市智能化水平的重要组成部分。随着作业规范化的推进、服务综合性的增强以及人口老龄化的加剧,环卫行业面临着诸多挑战和新问题。AI技术的快速发展为解决这些难题提供了有力的支持。它不仅推动了设施的智能化管理,还实现了运营管理的信息化和决策分析的智慧化,从而提高了整体运营效率和服务质量。在当前严峻的环保形势下,保护环境是至关重要的任务。这要求我们在日常工作中严格遵循环境保护法规,合理利用资源,减少污染排放,并积极采用新技术、新方法来改善城市环境质量。同时,我们也要持续关注行业趋势变化,不断提升自身技术实力,为实现城市的可持续发展贡献力量。
1.3.项目介绍
使用ResNet经网络对道路进行分类,识别并标记出包含垃圾和干净的路段,有效减少了人工劳动需求。
2.数据集处理
2.1.数据集解压缩
首先想要训练一个神经网络,至少要有数据集,所以我们要从这里开始!、
解压缩数据集,默认压缩为目前路径。后面也可跟-d 完整路径/相对路径 In [2]
! unzip -oq /home/aistudio/data/data199856/archive.zip登录后复制
2.2.数据集分离训练集和测试集
该项目中我采用自定义数据集的方式进行模型训练,因此需要编写代码来记录图片路径和对应的标签信息,并将其分别存储在train文本文档和text文本文档中。为了确保良好的测试与训练数据分离,我会使用比例将数据分为测试集和训练集。在这个过程中,我也会注意到Jupyter Notebook 为了自动保存文件而创建的文件夹.ipynb_checkpoints。这个文件夹会在你编辑并保存Jupyter Notebook中的文档时自动建立,并在其中保存当前文档的副本以备不时之需。因此,在处理txt文件时,我们需要确保删除掉这些可能隐藏在文件系统中的临时副本文件。
操作系统中的os模块专注于文件系统操作,帮助创建和访问文件,并提供必要的信息以实现各种需求。
import osimport cv2 basedir=r'/home/aistudio/Images/Images' #基础文件list_dir=os.listdir(basedir) #获取图片文件夹中的图片名称并存放到列表中if '.ipynb_checkpoints' in list_dir: #如果含有该文件,删除该文件,防止写入txt文件当中 list_dir.remove('.ipynb_checkpoints') clean=[];ditty=[]for i in list_dir: if 'clean' in i : clean.append(i) else: ditty.append(i) #以1:4的比例划分训练集以及测试集with open('test_label.txt','w') as file: #写测试集的图片路径以及所对应的标签 for i in range(int(len(clean)/5)): file.write(f'{clean[i]} 0\n') for j in range(int(len(ditty)/5)): file.write(f'{ditty[j]} 1\n')with open('train_label.txt','w') as file: #写训练集的图片路径以及所对应的标签 for i in range(int(len(clean)/5),len(clean)): file.write(f'{clean[i]} 0\n') for j in range(int(len(ditty)/5),len(ditty)): file.write(f'{ditty[j]} 1\n')登录后复制
2.3.数据预处理
在训练之前时,要进行数据预处理,数据预处理如下:
RandomResizedCrop是将输入图像按照随机大小和长宽比进行裁剪
RandomHorizontalFlip是基于概率来执行图片的水平翻转
ToTsensor将 PIL.Image 或 numpy.ndarray 转换成 paddle.Tensor。
Normalize是将输入数据调整为指定大小。
Compose是将用于数据集预处理的接口以列表的方式进行组合。
如果有其他想知道可以去官网看
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓
官方文档数据预处理 In [4]
import paddle.vision.transforms as transforms data_transform = { "train": transforms.Compose([transforms.RandomResizedCrop(224), transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]), "val": transforms.Compose([transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}登录后复制
2.4.使用 paddle.io.Dataset 自定义数据集
本项目需自定义道路检测数据集,如文档中所述,主要包含图像预处理步骤:在数据预处理时增加了RandomResizedCrop,旨在增强训练样本多样性。由于灰度图无法被传统方法处理,因此需要特殊处理策略,确保其正常参与模型训练过程。以下是各关键部分注释的详细介绍,确保您的项目顺利进行。
新的在处理图像数据时,我们通常需要进行预处理、训练和测试。本篇文章提供了一个完整的Python代码示例,展示了如何将Paddle框架中的Dataset类继承起来,并使用它来加载图像数据和标签信息。这个例子特别关注于训练集的创建。首先,定义一个名为MyDataset的新类,该类继承自paddle.io.Dataset。在初始化方法__init__中,读取训练和测试样本文件(train_label.txt和test_label.txt),并将其内容转换为列表格式。对于每个图像路径及其对应标签信息,都将这些数据存储在一个包含图像和标签的元组列表中。然后,在__getitem__函数中,定义了如何从列表中获取特定索引的数据以及对图像进行预处理的操作。特别注意的是,此示例将Paddle框架中的image类型转换为标准的numpy.ndarray,确保了后续操作时能够正确处理图像数据格式。在__len__方法中,实现了返回MyDataset实例数据集大小的功能,这是构建完整训练或测试数据集所必需的一部分信息。最后,在整个代码段之后,我们打印出训练和测试样本的数据量,进一步验证我们的数据加载和预处理是否成功。通过遍历一个训练样例并打印其图像形状和显示图像的函数演示了如何对这些数据进行处理,并确保了良好的可视化效果。本文提供了一个详细的例子,展示了从加载、预处理到展示图像的完整过程,这在Paddle框架中处理大量图像时非常有用。
train_custom_dataset images: 192 test_custom_dataset images: 46 shape of image: [3, 224, 224]登录后复制
<Figure size 640x480 with 1 Axes>登录后复制登录后复制
如果遇到输出时报红,不必惊慌,那是系统提示;但使用Python 写的某些代码可能在升级到Python 失效。为了避免这种问题,在两台计算机上尝试运行它们即可避免警告。

1.5.使用 paddle.io.DataLoader 定义数据读取器
上述的操作只是将我们的数据构造成了训练数据集和测试数据集
下面的操作是将迭代读取数据集,只有这样子才可以放到神经网络中进行‘ 炼丹 ’。 In [7]
从Paddle Paddle库中导入必要的模块。创建一个训练数据流处理器(`train_loader`)用于批次的训练,同时设置随机打乱模式、使用多线程和保留剩余批次中的最后一个数据以处理缺失值。接着,创建一个测试数据流处理器(`test_loader`),同样采用相同的配置参数。在训练过程(通过遍历`train_loader`并打印当前批次的数据及其shape)与测试过程(通过遍历`test_loader`并打印相同信息)中,都会打印出所处理数据的形状。这样可以清晰地监控和验证数据预处理的正确性。
batch_id: 0, 训练数据shape: [32, 3, 224, 224], 标签数据shape: [32] batch_id: 0, 测试数据shape: [32, 3, 224, 224], 标签数据shape: [32]登录后复制
3.Resnet网络
3.1.什么是resnet网络
ResNet在由微软实验室的何凯明等几位专家提出,成为当年ImageNet竞赛中分类和目标检测任务的冠军,并在COCO数据集上分别获得了第一名的成绩。自此,ResNet模型被广泛应用于计算机视觉领域,其残差结构仍被广泛应用至今。该项目以ResNet为模板,构建了新一代神经网络体系。
3.2.网络中的亮点
构建深度神经网络时,采用更深层次的设计(最高可达)。 引入ResNet架构中的残差连接,显著提升学习效率。 实施Batch Normalization,有效减少过拟合并加速训练过程。
3.3.网络特点residual结构
ESIM采用了短路连接的方式,也可以称为捷径。通过在特征矩阵上隔行相加,确保了输入和输出之间的对应关系,即F(X)的形状与输入X相同。这种处理方式使得网络能够在一定程度上学习到之前未见过的信息,从而增强了模型的泛化能力。
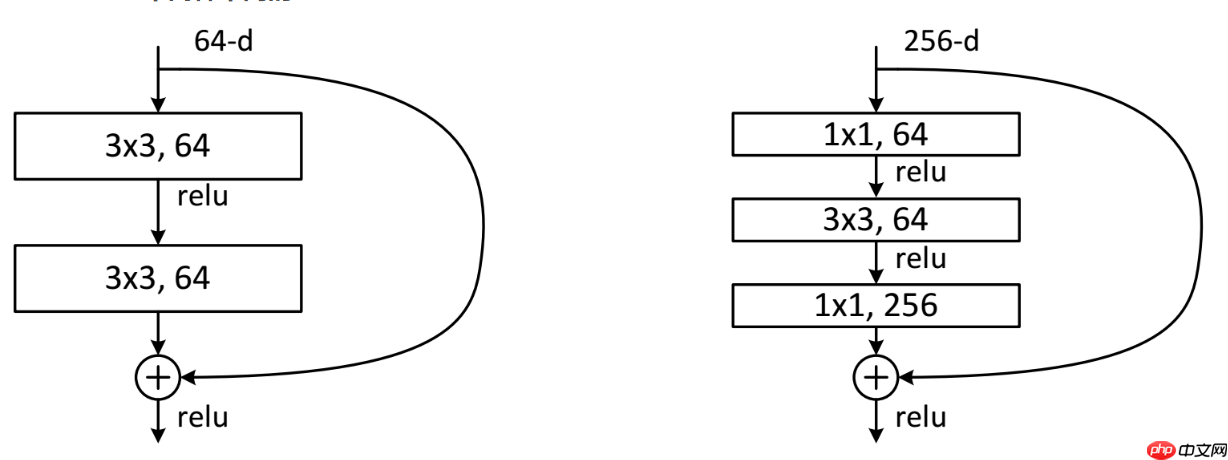
3.4.手工搭建神经网络
已完成数据集预处理,现需构建好环境以便于高效地进行模型训练。
基本的网络结构就是如下
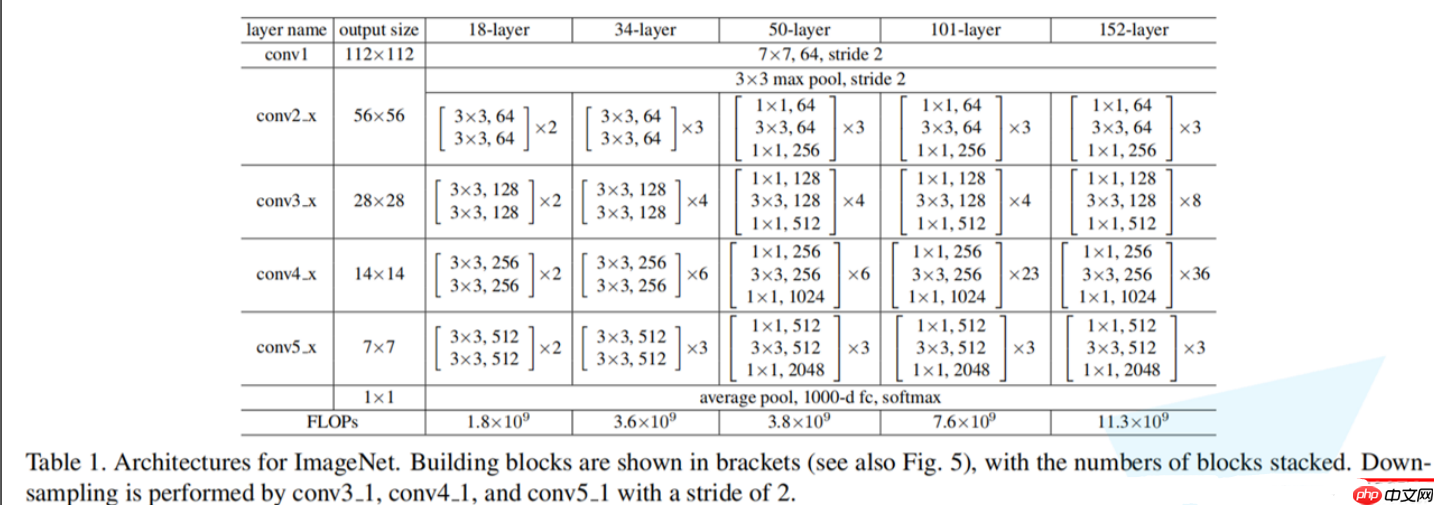
开始搭建网络!
在构建网络时,先观察上层结构,然后按顺序编写代码,确保遵守Conv之后紧接BatchNorm和ReLU的规定。
在深度学习中,Batch Norm作为批归一化层实现了一种便捷的方法。它允许你通过批量数据统计,对卷积或全连接操作中的输入数据进行快速标准化处理,以加速训练过程并提高模型性能。这种功能特别适用于需要高效和准确建模的场景。
RELU:稀疏 ReLU 激活层,创建一个可调用对象以计算输入 x 的 ReLU 。ReLU(x)=max(x,0) In []
Paddle实现了深度学习模型的自动生成和优化,通过导入相关的库,我们创建了一个名为resnet新类。该网络结构包含了卷积层、池化层以及全连接层,适用于图像分类任务。它首先通过一个小的积层对输入数据进行处理,并进行了步长为下采样操作。然后,它将输入向量扩展到。在网络的最后一部分,我们使用了一个平均池化层和两个最大池化层来提取特征。最后,我们将这些特征映射到,并通过一个全连接层输出结果。此外,我们还提供了残差网络模块的实现,这使得我们的模型能够学习更复杂的表达能力。对于数据格式为Paddle中的张量输入,该代码生成了详细的参数信息。
3.训练阶段
3.1.定义优化器以及损失函数
一个完整的模型除了有神经网络还有所对应的优化器以及损失函数,如下面所示 In [14]
```python import paddle# 将ResNet模型及其所有子层设置为训练模式。 net.train# 创建Adam优化器并指定学习率 optim = paddle.optimizer.Adam(learning_rate= parameters=net.parameters)# 定义交叉熵损失函数 loss_fun = paddle.nn.CrossEntropyLoss ```
3.2.开始训练
In []
# 设置迭代次数epochs = 36paddle.device.set_device('gpu:0') bestacc=0for epoch in range(epochs): net.train() for batch_id, data in enumerate(train_loader()): x_data = data[0] # 训练数据 y_data = data[1] # 训练数据标签 predicts = net(x_data) # 预测结果 # 计算损失 loss = loss_fun(predicts, y_data) # 反向传播 loss.backward() if (batch_id) % 2 == 0: acc=(np.sum(predicts.argmax(1).numpy()==y_data.numpy()))/len(y_data) print("train epoch: {}, batch_id: {}, loss is: {}, acc is: {}".format(epoch, batch_id+1, loss.numpy(), acc)) # 更新参数 optim.step() # 梯度清零 optim.clear_grad() if epoch % 5==0: net.eval() for batch_id, data in enumerate(test_loader()): x_data = data[0] # 测试数据 y_data = data[1] # 测试数据标签 predicts = net(x_data) # 预测结果 # 计算损失与精度 loss = loss_fun(predicts, y_data) # 打印信息 acc=(np.sum(predicts.argmax(1).numpy()==y_data.numpy()))/len(y_data) print("test batch_id: {}, loss is: {}, curr_acc is: {} bestacc is {}".format(batch_id+1, loss.numpy(), acc, bestacc)) if bestacc<acc: bestacc=acc paddle.save(net.state_dict(), "resnet1_net.pdparams")登录后复制
由于数据集不是很多,所以导致数据的精确不是很高,只有90%左右的准确率,不过也是够用了。
4.预测阶段
4.1.测试集预测
在评估过程中,我们将最准确的模型权重保留下来,并将测试集用于预测道路状况。然后输出总的准确率。
预训练网络为resnet加载模型参数: ```python layer_state_dict = paddle.load('/home/aistudio/resnetnet.pdparams') pre_net.set_state_dict(layer_state_dict) pre_net.eval#使用测试集来看看精度 for batch_id, data in enumerate(test_loader): x_data = data[ # 测试数据 y_data = data[ # 测试标签 predicts = pre_net(x_data) # 预测结果 print(predicts.numpy) print('预测的标签信息为:', predicts.argmax(.numpy) print('真实的标签信息为:', y_data.numpy) acc = (np.sum(predicts.argmax(.numpy == y_data.numpy)) / len(y_data) print(test batch_id: {} acc is: {}.format(batch_id, acc))```
4.2.个体预测
使用单一图片与新增维度后,可以直接导入至神经网络以识别道路清洁状况。
import paddle image=cv2.imread(r'/home/aistudio/Images/Images/clean_7.jpg') image=data_transform['val'](image) plt.rcParams['font.sans-serif']=['FZHuaLi-M14S'] plt.imshow(image[0]) plt.title('') image=paddle.reshape(image,[1,3,224,224]) predict=pre_net(image)print(predict.numpy()) #明显可以看出是第0个标签大,即干净的道路if predict.argmax(1)==0: plt.title('干净的道路')else: plt.title('不干净的道路') plt.show()登录后复制
[[2.4930854 1.1419637]]登录后复制
<Figure size 640x480 with 1 Axes>登录后复制登录后复制
以上就是【AI达人训练营第三期】手工搭建Resnet101分类道路情况的详细内容,更多请关注其它相关文章!
相关下载
相关资讯
猜你喜欢
最新资讯
-

三星Galaxy A56运行内存是多大
2025-08-10
手机配置的重要性不言而喻,不同的手机在性能规格上确实存在差异。例如,运行内存容量大小也会影响用户的使用体验
-

《真三国无双》25周年纪念周边商品介绍:月香草
2025-08-10
继耳饰后,光荣再次在官推发布了《真三国无双》系列25周年纪念周边商品介绍,这一次是月香草(香薰)。商品介绍:在新作真三国无双:起源中出现了的月香草主题芳香产品
-

立秋是2025的几月几日几点 今年立秋的时间是几点几分
2025-08-10
对于标题中提到的具体时间,通过天文测算得知,立秋的确切时间为。而今年立秋则在公历早上。这两个时间上的差异,源于地球公转轨道的复杂性和历法计算的精确度